Регрессия Кокса, или модель пропорциональных рисков
Описание метода
Регрессия Кокса, или модель пропорциональных рисков, — прогнозирование риска наступления события для рассматриваемого объекта и оценка влияния заранее определенных независимых переменных (предикторов) на этот риск. Риск рассматривается как функция, зависящая от времени. Заметим, поскольку риск — это не вероятность, он может принимать значения больше 1.
Объектом (наблюдением) может быть пациент, заемщик, клиент, для которого прогнозируется риск наступления события. Этот объект априори находится под наблюдением и поэтому входит в группу риска: в любой отрезок времени с ним может наступить событие, при котором он выбывает из группы риска.
В качестве события может рассматриваться смерть пациента, дефолт заемщика или отказ клиента от услуг, соответственно речь идет о риске того, что пациент в рассматриваемый период умрет, не сможет платить по кредиту, перестанет пользоваться услугами компании.
Время — период от момента, когда объект попал под наблюдение (был занесен в группу риска) до момента, когда для объекта наступило событие: время жизни пациента, время наступления дефолта, время «ухода» клиента. Оно может измеряться в секундах, месяцах, годах.
Независимые переменные (предикторы) — характеристики объекта (например, возраст пациента, доход заемщика, сервисный пакет услуг, выбранный клиентом), которые могут влиять на риск наступления события.
В основе метода три базовых предположения:
- Все объясняющие переменные независимы.
- Все объясняющие переменные линейно влияют на риск наступления события.
- Риски наступления события для любых двух объектов в любой отрезок времени пропорциональны.
Исходя из этого, выводится формула, по которой риск наступления события для i-того объекта имеет вид:
![]()
где
h0(t) — базовый риск, одинаковый для всех объектов;
β1, …, βp — коэффициенты;
X1 , …, Xp — независимые переменные, предикторы.
Базовый риск h0(t) — риск наступления события для объекта из референтной группы (при этом все независимые переменные X1 , …, Xp равны нулю).
Коэффициенты β1, …, βp показывают влияние каждого предиктора на функцию риска:
при увеличении значения предиктора Xj на единицу (при том, что значения остальных переменных не изменились) риск наступления события возрастает в exp (βj) раз.
Как видим, модель пропорциональных рисков весьма схожа с логистической регрессией. Обе они строятся с помощью методов пошагового включения/исключения переменных в модель.
Сбор и подготовка данных для модели
Телекоммуникационная компания предпринимает попытки сократить отток клиентов. Она заинтересована в том, чтобы определить факторы, которые влияют на отказ пользователей от услуг провайдера. Мы используем регрессию Кокса для того, что изучить, как меняется риск наступления события (отказ клиента от услуг компании) в зависимости от того, как долго объект (клиент компании) уже находится в группе риска, а также определить насколько важными являются другие его характеристики (пол, возраст, образование, размер семьи и др.) и как каждая из них влияет на риск наступления события. С точки зрения практической ценности для анализа оттока руководство компании особо интересуют выделенные отделом маркетинга потребительские категории.
Объектами нашего исследования являются 1000 клиентов в возрасте старше 18 лет (переменная ВОЗРАСТ). Поскольку под событием мы понимаем отказ клиента от услуг компании, целевую группу составили только те клиенты, которые определенный период времени пользовались услугами провайдера, а затем через какое-то время отказались от них. Таким образом, из анализа исключаются 274 респондента, которые перестали быть клиентами компании, в группе риска остается 726 человек, на наблюдении за которыми и будет построен анализ. Группа риска состоит из клиентов, которые продолжают пользоваться услугами компании. В нашем примере событие — отказ от услуг: как только клиент перестал пользоваться услугами провайдера, он выбывает из группы риска.
Кроме информации о точном времени наступления события (или ненаступления) в жизни респондента до момента окончания наблюдения, мы обладаем информацией о 12 дополнительных характеристиках каждого клиента:
ГЕОГРАФИЧЕСКИЙ ИНДИКАТОР
ВРЕМЯ ПОЛЬЗОВАНИЯ УСЛУГАМИ В МЕСЯЦАХ
ВОЗРАСТ
СЕМЕЙНОЕ ПОЛОЖЕНИЕ
ВРЕМЯ ПРОЖИВАНИЯ ПО НАСТОЯЩЕМУ АДРЕСУ
ДОХОД ДОМОХОЗЯЙСТВА В ТЫСЯЧАХ
УРОВЕНЬ ОБРАЗОВАНИЯ
ВРЕМЯ РАБОТЫ НА ПОСЛЕДНЕМ МЕСТЕ РАБОТЫ
УХОД НА ПЕНСИЮ
ПОЛ
КОЛИЧЕСТВО ЧЛЕНОВ ДОМОХОЗЯЙСТВА
ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ
Они могут влиять на риск наступления события.
Как только респондент начинает пользоваться услугами компании, у него появляется риск отказаться от них. Это обозначает, что он попадает в группу риска быть подвергнутым событию, и в этот момент мы начинаем за ним наблюдение (начинается отсчет времени, используется переменная time = 0 месяцев).
В момент, когда респондент отказывается от услуг компании, наступает событие: статусной переменной status присваивается значение 1, обозначающее наступление события, счетчик времени останавливается, time равен количеству месяцев, прошедших с момента, когда респондент стал клиентом компании (time = 0).
Если на момент опроса клиент продолжает пользоваться услугами компании, счетчик времени тоже останавливается, а переменной status присваивается значение 0. В этом случае time равен количеству месяцев, прошедших с момента, когда респондент стал клиентом компании (когда был time = 0) до момента окончания наблюдения (момента опроса).
В качестве единицы измерения времени выбран месяц.
Таким образом, в нашем исследовании:
Событие — отказ клиента от услуг провайдера.
Время — количество месяцев от момента, когда клиент начал пользоваться услугами провайдера, до момента, когда он отказался от них.
Группа риска — клиенты, продолжающие пользоваться услугами компании (1000 — 274 = 726 респондентов).
Объясняющие переменные — 12 дополнительных характеристик клиента.
Настройка и запуск процедуры анализа
Пошагово проиллюстрируем применение Регрессии Кокса с помощью SPSS.
Чтобы запустить процедуру построения Регрессия Кокса:
|
► Выберите в меню Analyze… ► Survival… ► Cox Regression. |
► Выберите в меню Анализ… ► Анализ выживаемости… ► Регрессия Кокса. |
Теперь, как показано на рис. 1:
|
► Поместите переменную time [ВРЕМЯ ПОЛЬЗОВАНИЯ УСЛУГАМИ В МЕСЯЦАХ] в поле Time. ► Поместите переменную status [ОТКАЗ В ТЕЧЕНИЕ ПОСЛЕДНЕГО МЕСЯЦА] в поле Status. |
► Поместите переменную time [ВРЕМЯ ПОЛЬЗОВАНИЯ УСЛУГАМИ В МЕСЯЦАХ] в поле Время. ► Поместите переменную status [ОТКАЗ В ТЕЧЕНИЕ ПОСЛЕДНЕГО МЕСЯЦА] в поле Статус. |
Рисунок 1
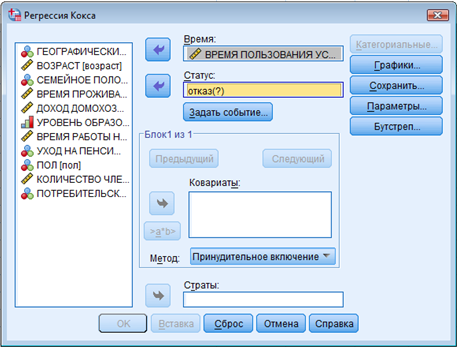
Переменная в поле Status (Статус) отражает наступление или ненаступление события на момент завершения наблюдения за данным респондентом.
|
► Щелкните Define Event. |
► Щелкните Задать событие. |
Как показано на рис. 2:
|
► Введите 1 в качестве значения переменной status, указывающего на то, что клиент перестал пользоваться услугами компании. ► Щелкните Continue. |
► Введите 1 в качестве значения переменной status, указывающего на то, что клиент перестал пользоваться услугами компании. ► Щелкните Продолжить. |
Рисунок 2
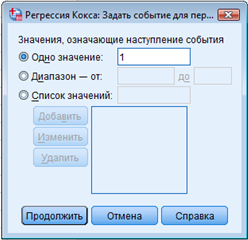
Данные шаги позволят нам построить функцию риска (шанса) отказа клиента от услуг компании и ее изменение в зависимости от продолжительности пользования услугами (с того момента, как респондент стал клиентом). Риск, как и time, меняется ежемесячно.
Как показано на рис. 3:
|
► Поместите независимые переменные [ВОЗРАСТ] [СЕМЕЙНОЕ ПОЛОЖЕНИЕ] [ВРЕМЯ ПРОЖИВАНИЯ ПО НАСТОЯЩЕМУ АДРЕСУ] [УРОВЕНЬ ОБРАЗОВАНИЯ] [ВРЕМЯ РАБОТЫ НА ПОСЛЕДНЕМ МЕСТЕ РАБОТЫ] [УХОД НА ПЕНСИЮ] [ПОЛ] [КОЛИЧЕСТВО ЧЛЕНОВ ДОМОХОЗЯЙСТВА] в поле Covariates. ► В качестве метода выберите Forward: LR — likelihood ratio. ► Щелкните Next в поле Block. |
► Поместите независимые переменные [ВОЗРАСТ] [СЕМЕЙНОЕ ПОЛОЖЕНИЕ] [ВРЕМЯ ПРОЖИВАНИЯ ПО НАСТОЯЩЕМУ АДРЕСУ] [УРОВЕНЬ ОБРАЗОВАНИЯ] [ВРЕМЯ РАБОТЫ НА ПОСЛЕДНЕМ МЕСТЕ РАБОТЫ] [УХОД НА ПЕНСИЮ] [ПОЛ] [КОЛИЧЕСТВО ЧЛЕНОВ ДОМОХОЗЯЙСТВА] в поле Ковариаты. ► В качестве метода выберите Пошаговое включение: ОП (отношение правдоподобия). ► Щелкните Следующий в поле Блок. |
Методом регрессионного оценивания по умолчанию в SPSS является Enter (Принудительное включение). Он подразумевает включение в регрессионное уравнение (модель) всех заданных предикторов независимо от того, оказывают ли они значимое влияние на функцию риска или нет. Однако данный метод лучше применять лишь в тех случаях, когда нам уже известно, какие именно переменные нужно включить в модель в качестве предикторов.
В основе метода Forward (Пошаговое включение) – пошаговое включение в уравнение предикторов в порядке убывания их объясняющей силы. И так до последнего предиктора, влияние которого будет значимым.
Метод Backward (Пошаговое исключение) стартует с максимального набора предикторов. Затем на каждом шаге из модели исключается наименее полезный из предикторов. Процедура останавливается, когда из модели больше нечего удалять, остались только хорошо объясняющие функцию риска независимые переменные.
Рисунок 3
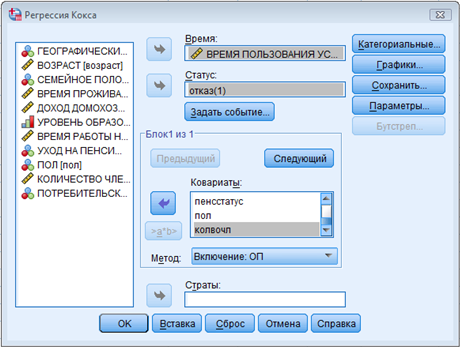
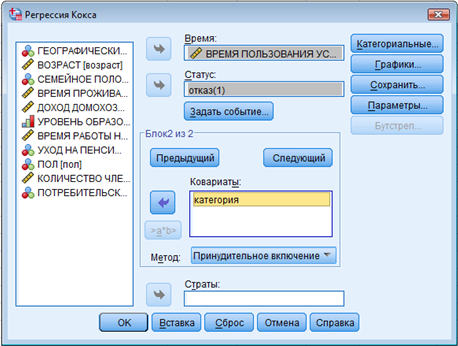
Как показано на рис. 4:
|
► Поместите переменную [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ] в поле Covariates. ► В качестве метода выберите Enter. Использование метода включения во втором блоке гарантирует нам, что переменная [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ] будет включена в модель. |
► Поместите переменную [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ] в поле Ковариаты. ► В качестве метода выберите Принудительное включение. Использование метода включения во втором блоке гарантирует нам, что переменная [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ] будет включена в модель. |
По умолчанию все независимые переменные считаются непрерывными. Если среди них есть категориальные переменные, то для каждой из них необходимо указать Categorical (Категориальные) и определить, какая категория считается опорной.
|
► Щелкните Categorical. |
► Щелкните Категориальные. |
Рисунок 4
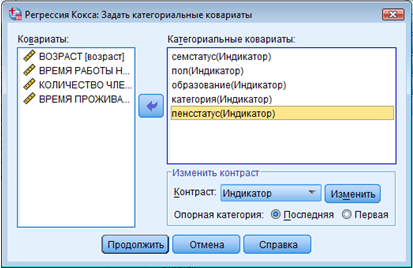
Как показано на рис. 5:
|
► Поместите переменные [СЕМЕЙНОЕ ПОЛОЖЕНИЕ] [УРОВЕНЬ ОБРАЗОВАНИЯ] [УХОД НА ПЕНСИЮ] [ПОЛ] [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ] в поле Categorical Covariates. ► Оставьте включенной опцию Last в поле Reference Category. ► Щелкните Continue. ► Щелкните Plots в диалоговом окне Cox Regression. |
► Поместите переменные [СЕМЕЙНОЕ ПОЛОЖЕНИЕ] [УРОВЕНЬ ОБРАЗОВАНИЯ] [УХОД НА ПЕНСИЮ] [ПОЛ] [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ] в поле Категориальные Ковариаты. ► Оставьте включенной опцию Последняя в поле Опорная категория. ► Щелкните Продолжить. ► Щелкните Графики в диалоговом окне Регрессия Кокса. |
Рисунок 5
Как показано на рис. 6:
|
► Выберите Survival и Hazard в поле Plot Type. ► Выберите Separate Lines for для переменной [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ]. ► Щелкните Continue. ► Щелкните OK в диалоговом окне Cox Regression. |
► Выберите Выживаемость и Риск в поле Тип графика. ► Выберите Отдельные линии для переменной [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ]. ► Щелкните Продолжить. ► Щелкните OK в диалоговом окне Регрессия Кокса. |
Рисунок 6
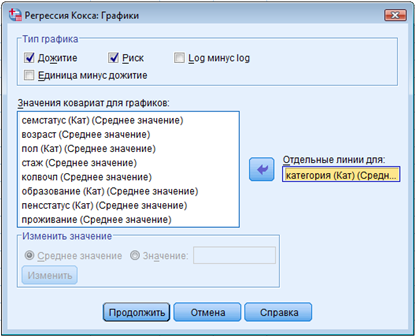
Таблица 1. Сводка обработки наблюдений
|
|
N |
Процент | |
|
Наблюдения, доступные в анализе |
Событиеa |
274 |
27,4% |
|
Цензурированные |
726 |
72,6% | |
|
Итого |
1000 |
100,0% | |
|
Опущенные наблюдения |
Наблюдения с пропущенными значениями |
0 |
,0% |
|
Наблюдения с отрицательным временем |
0 |
,0% | |
|
Наблюдения, цензурированные до наступления первого события в страте |
0 |
,0% | |
|
Итого |
0 |
,0% | |
|
Итого |
1000 |
100,0% | |
a. Зависимая переменная: ВРЕМЯ ПОЛЬЗОВАНИЯ УСЛУГАМИ В МЕСЯЦАХ
Статусная переменная определяет, произошло ли событие в данном наблюдении. Если событие не произошло, то принято говорить, что наблюдение является цензурированным. Цензурированные наблюдения не используются в вычислении коэффициентов регрессии, но применяются для вычисления базового риска.
Сводка результатов (табл. 1) показывает, что 726 наблюдений являются цензурированными. Это клиенты, которые не отказались от услуг компании.
Таблица 2. Кодировка категориальных переменныхc,d,e,f,g
|
|
Частота |
(1)b |
(2) |
(3) |
(4) | |
|
семстатусa |
0=ХОЛОСТ (НЕ ЗАМУЖЕМ) |
505 |
1 |
|
|
|
|
1=ЖЕНАТ (ЗАМУЖЕМ) |
495 |
0 |
|
|
| |
|
образованиеa |
1=НЕЗАКОНЧЕННОЕ СРЕДНЕЕ ОБРАЗОВАНИЕ |
204 |
1 |
0 |
0 |
0 |
|
2=ЗАКОНЧЕННОЕ СРЕДНЕЕ ОБРАЗОВАНИЕ |
287 |
0 |
1 |
0 |
0 | |
|
3=НЕЗАКОНЧЕННОЕ ВЫСШЕЕ ОБРАЗОВАНИЕ |
209 |
0 |
0 |
1 |
0 | |
|
4=ЗАКОНЧЕННОЕ ВЫСШЕЕ ОБРАЗОВАНИЕ |
234 |
0 |
0 |
0 |
1 | |
|
5=УЧЕНАЯ СТЕПЕНЬ |
66 |
0 |
0 |
0 |
0 | |
|
пенсстатусa |
,00=НЕТ |
953 |
1 |
|
|
|
|
1,00=ДА |
47 |
0 |
|
|
| |
|
полa |
0=МУЖСКОЙ |
483 |
1 |
|
|
|
|
1=ЖЕНСКИЙ |
517 |
0 |
|
|
| |
|
категорияa |
1=БАЗОВЫЕ УСЛУГИ |
266 |
1 |
0 |
0 |
|
|
2=ЭЛЕКТРОННЫЕ УСЛУГИ |
217 |
0 |
1 |
0 |
| |
|
3=ПЛЮС УСЛУГИ |
281 |
0 |
0 |
1 |
| |
|
4=ВСЕ УСЛУГИ |
236 |
0 |
0 |
0 |
| |
a. Кодировка параметра: индикатор
b. Переменная (0,1) была перекодирована, поэтому коэффициенты для этой переменной не будут совпадать с коэффициентами для индикатора с кодировкой (0,1).
c. Категориальная переменная: семстатус (СЕМЕЙНОЕ ПОЛОЖЕНИЕ)
d. Категориальная переменная: образование (УРОВЕНЬ ОБРАЗОВАНИЯ)
e. Категориальная переменная: пенсстатус (УХОД НА ПЕНСИЮ)
f. Категориальная переменная: пол (ПОЛ)
g. Категориальная переменная: категория (ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ)
Кодировки категориальных переменных, приведенные в табл. 3, нужны для интерпретации регрессионных коэффициентов для категориальных переменных, особенно для дихотомических переменных.
Если для анализа используется номинальная или порядковая независимая переменная, принимающая k значений, то, чтобы она была пригодна для анализа, ее нужно перекодировать в k-1 дамми-переменных (или в k, но в анализе использовать только k-1).
В диалоговом окне, приведенном на рис. 5, мы как раз создаем дамми-переменные.
Например, у нас есть переменная [СЕМЕЙНОЕ ПОЛОЖЕНИЕ], которая принимает следующие значения: 0 — ХОЛОСТ (НЕ ЗАМУЖЕМ), 1 — ЖЕНАТ (ЗАМУЖЕМ).
Если для нее в качестве опорной категории выбрана Last (в нашем случае это 1 «ЖЕНАТ (ЗАМУЖЕМ)»), это обозначает, что переменная [СЕМЕЙНОЕ ПОЛОЖЕНИЕ] со значениями 0 «ХОЛОСТ (НЕ ЗАМУЖЕМ)»/1 «ЖЕНАТ (ЗАМУЖЕМ)» перекодируется, как показано в табл. 1, в дамми-переменную со значениями 1 «ХОЛОСТ (НЕ ЗАМУЖЕМ)»/0 «ЖЕНАТ (ЗАМУЖЕМ)».
Таблица 3. Пример дамми-кодирования
|
|
Кодирование параметра | ||
|
(1) |
(2) | ||
|
СЕМЕЙНОЕ ПОЛОЖЕНИЕ |
0 ХОЛОСТ (НЕ ЗАМУЖЕМ) |
1 |
|
|
1 ЖЕНАТ (ЗАМУЖЕМ) |
0 |
| |
Эта новая дамми-переменная будет включена в регрессию, и коэффициент для нее указывает, насколько риск оттока для холостых клиентов выше или ниже, чем для женатых. Интерпретация будет следующей: по сравнению с женатыми у холостых риск ухода выше или ниже в столько-то раз.
По умолчанию опорной является «последняя» категория переменной.
Таким образом, даже несмотря на то, что, например, категория «Женат/замужем» переменной [Семейный статус клиента] кодируется значением 1, она в целях регрессионного анализа будет кодироваться 0.
Если вы хотите перекодировать переменную [СЕМЕЙНОЕ ПОЛОЖЕНИЕ] так, чтобы значение 1, заданное в Редакторе данных/Редакторе переменных, кодировалось в регрессионном анализе как 1, измените для нее опорную категорию с «последней» на «первую» во вкладке «Категориальные Ковариаты».
Та же процедура перекодировки применяется к категориальным переменным, имеющим больше двух значений. Например [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ], принимающая 4 значения от 1 до 4 с референтной группой Last, будет автоматически переделана в 3 дамми-переменных вида 1/0, эти новые 3 переменных будут включены в регрессию, и коэффициент при каждой из них будет указывать отличие группы респондентов с данным значением [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ] от группы респондентов со значением [категория] = 4.
Таблица 4. Объединенные Тесты коэффициентов моделиf для Блока 1
|
Шаг |
-2 Log Правдоподобия |
Общий (балл) |
Отличие от предыдущего шага |
Отличие от предыдущего блока | ||||||
|
Хи-Квадрат |
ст.св. |
Знч. |
Хи-Квадрат |
ст.св. |
Знч. |
Хи-Квадрат |
ст.св. |
Знч. | ||
|
1a |
3383,793 |
132,522 |
1 |
,000 |
142,571 |
1 |
,000 |
142,571 |
1 |
,000 |
|
2b |
3331,588 |
161,504 |
2 |
,000 |
52,205 |
1 |
,000 |
194,776 |
2 |
,000 |
|
3c |
3295,644 |
178,903 |
3 |
,000 |
35,943 |
1 |
,000 |
230,720 |
3 |
,000 |
|
4d |
3295,688 |
174,203 |
2 |
,000 |
,044 |
1 |
,834 |
230,676 |
2 |
,000 |
|
5e |
3282,533 |
186,817 |
3 |
,000 |
13,155 |
1 |
,000 |
243,831 |
3 |
,000 |
a. Переменная(ые), включенная(ые) на шаге номер 1: возраст
b. Переменная(ые), включенная(ые) на шаге номер 2: стаж
c. Переменная(ые), включенная(ые) на шаге номер 3: проживание
d. Переменная(ые), исключенная(ые) на шаге номер 4: возраст
e. Переменная(ые), включенная(ые) на шаге номер 5: семстатус
f. Начало Блока Номер 1. Метод = Включение (Отношение правдоподобия)
Согласно настройкам, процесс построения модели осуществляется двумя блоками. Первым используется метод прямого включения.
В табл. 4 приводятся показатели того, насколько хорошо построена наша модель для первого блока. Изменение статистики хи-квадрат по сравнению с предыдущим шагом — это различие между удвоенным логарифмическим правдоподобием модели на предыдущем и текущем шаге.
Если на данном шаге должна быть добавлена какая-либо переменная, то включение имеет смысл, если статистическая значимость изменения меньше, чем 0.05.
Если на данном шаге должна быть исключена какая-либо переменная, то исключение имеет смысл, если статистическая значимость изменения больше, чем 0.10.
На первых трех шагах в модель включены переменные [возраст], [стаж] и [проживание].
На четвертом шаге переменная [возраст] исключена из модели, вероятно, потому, что вариация времени ухода, объясненная переменной [возраст], также объясняется переменными [стаж] и [проживание]. Таким образом, эти переменные включены в модель, а переменная [возраст] больше не нужна.
Наконец, на пятом шаге включена переменная [семстатус].
Таблица 5. Переменные в уравнении для Блока 1
|
|
В |
Стд.Ошибка |
Вальд |
ст.св. |
Знч. |
Ехр(В) | |
|
Шаг 1 |
возраст |
-,065 |
,006 |
124,361 |
1 |
,000 |
,937 |
|
Шаг 2 |
возраст |
-,032 |
,007 |
22,806 |
1 |
,000 |
,969 |
|
стаж |
-,075 |
,011 |
49,296 |
1 |
,000 |
,928 | |
|
Шаг 3 |
возраст |
-,002 |
,008 |
,044 |
1 |
,835 |
,998 |
|
проживание |
-,059 |
,010 |
35,184 |
1 |
,000 |
,942 | |
|
стаж |
-,080 |
,011 |
53,479 |
1 |
,000 |
,923 | |
|
Шаг 4 |
проживание |
-,060 |
,009 |
49,638 |
1 |
,000 |
,941 |
|
стаж |
-,081 |
,010 |
71,408 |
1 |
,000 |
,922 | |
|
Шаг 5 |
семстатус |
,442 |
,122 |
13,117 |
1 |
,000 |
1,556 |
|
проживание |
-,061 |
,009 |
50,409 |
1 |
,000 |
,941 | |
|
стаж |
-,083 |
,010 |
73,287 |
1 |
,000 |
,920 | |
Из табл. 5 видно, что итоговая модель для блока 1 включает переменные [семстатус], [срокпроживан] и [стаж].
Exp(B) — спрогнозированное изменение риска при изменении значения независимой переменной на единицу.
Выявлены значительные взаимосвязи для случаев оттока клиентов по трем независимым переменным.
Значение Exp(B) для переменной [семстатус] равно 1.556. Из кодировок категориальных переменных мы помним, что категории «не женат (не замужем)» в регрессионном анализе соответствует значение 1 (а не 0, как в Редакторе данных). Это обозначает, что для неженатых клиентов риск оттока в 1.556 раза выше, чем для женатых клиентов.
Значение Exp (B) для переменной [проживание] равно 0.941. Это обозначает, что риск оттока снижается на 100%-(100%x0.941)=5.9% с каждым годом проживания клиента по одному и тому же адресу. Риск оттока для клиента, который проживает по одному и тому же адресу 5 лет, снижается на 100%-(100%x(0.9415))=26.2%.
Значение Exp (B) для переменной [стаж] равно 0.920. Это обозначает, что риск оттока снижается на 100%-(100%x0.920)=8.0% с каждым годом работы клиента в одной и той же компании. Риск оттока для клиента, который занят на одном и том же месте работы 3 года, снижается на 100%-(100%x(0.9203))=22.1%.
Таблица 6. Объединенные Тесты коэффициентов моделиa для Блока 2
|
-2 Log Правдоподобия |
Общий (балл) |
Отличие от предыдущего шага |
Отличие от предыдущего блока | ||||||
|
Хи-Квадрат |
ст.св. |
Знч. |
Хи-Квадрат |
ст.св. |
Знч. |
Хи-Квадрат |
ст.св. |
Знч. | |
|
3253,012 |
213,600 |
6 |
,000 |
29,521 |
3 |
,000 |
29,521 |
3 |
,000 |
a. Начало Блока Номер 2. Метод = Принудительное включение
В табл. 6 приводятся показатели того, насколько хорошо построена наша модель для второго блока. Мы смотрим изменение по сравнению с предыдущим шагом и изменение по сравнению с предыдущим блоком. Они информируют нас о том, как добавление переменной [категория] влияет на модель. Напомним, эту переменную мы выбрали в блоке 2.
Поскольку значимость изменения меньше, чем 0.05, то можно быть уверенным, что переменная [категория] вносит свой вклад в модель.
Таблица 7. Переменные в уравнении для Блока 2
|
|
В |
Стд.Ошибка |
Вальд |
ст.св. |
Знч. |
Ехр(В) |
|
семстатус |
,432 |
,123 |
12,358 |
1 |
,000 |
1,541 |
|
проживание |
-,061 |
,009 |
49,768 |
1 |
,000 |
,940 |
|
стаж |
-,081 |
,010 |
67,141 |
1 |
,000 |
,922 |
|
категория |
|
|
28,506 |
3 |
,000 |
|
|
категория(1) |
,121 |
,155 |
,612 |
1 |
,434 |
1,129 |
|
категория(2) |
-,574 |
,170 |
11,450 |
1 |
,001 |
,563 |
|
категория(3) |
-,658 |
,186 |
12,479 |
1 |
,000 |
,518 |
На табл. 7 видно, что регрессионные коэффициенты для первых трех уровней переменной [категория] сравниваются с опорной категорией — клиентами, которые пользуются сервисным пакетом «ВСЕ УСЛУГИ».
Например, регрессионный коэффициент Exp(B) для первой категории — клиентов, пользующихся пакетом «БАЗОВЫЕ УСЛУГИ», равен 1.129. Это обозначает, что риск оттока у клиентов, выбравших пакет «БАЗОВЫЕ УСЛУГИ», в 1.129 раза больше, чем у клиентов, выбравших «ВСЕ УСЛУГИ».
Однако уровень значимости этого коэффициента равен 0.434, это больше, чем 0.10, поэтому наблюдаемое различие между этими категориями могло быть случайным.
Уровни значимости для второй и третьей категорий (соответствуют клиентам, выбравших пакеты «ЭЛЕКТРОННЫЕ УСЛУГИ» и «ПЛЮС УСЛУГИ») меньше, чем 0.05. Таким образом, между этими клиентами и клиентами, предпочитающими пакет «ВСЕ УСЛУГИ», есть статистически значимое различие.
Риск оттока для клиентов, выбравших пакет «ЭЛЕКТРОННЫЕ УСЛУГИ» в 0.563 раза меньше (или на 44% ниже), чем для клиентов, пользующихся пакетом «ВСЕ УСЛУГИ».
Риск оттока для клиентов, выбравших пакет «ПЛЮС УСЛУГИ» в 0.518 раз меньше (или на 48% ниже), чем для клиентов, пользующихся пакетом «ВСЕ УСЛУГИ».
Таблица 8. Переменные не включенные в уравнениеa
|
|
МЛ |
ст.св. |
Знч. |
|
возраст |
,134 |
1 |
,715 |
|
образование |
8,628 |
4 |
,071 |
|
образование(1) |
2,869 |
1 |
,090 |
|
образование(2) |
1,150 |
1 |
,283 |
|
образование(3) |
,070 |
1 |
,791 |
|
образование(4) |
5,519 |
1 |
,019 |
|
пенсстатус |
,563 |
1 |
,453 |
|
пол |
,128 |
1 |
,720 |
|
колвочл |
1,195 |
1 |
,274 |
a. Остаточный хи-квадрат = 10,317 с 8 ст.св. Знач. = ,244
В табл. 8 приводятся переменные, исключенные из модели. Все они имеют значения, уровень значимости которых больше, чем 0.05. При этом заметим, что уровень значимости для переменной [образование], равный 0.071, хоть и не меньше 0.05, но приближается к этому значению. Данная переменная может представлять интерес для дальнейшего анализа.
Таблица 9. Средние ковариат и значения структуры
|
|
Среднее |
Структура | |||
|
1 |
2 |
3 |
4 | ||
|
возраст |
41,684 |
41,684 |
41,684 |
41,684 |
41,684 |
|
семстатус |
,505 |
,505 |
,505 |
,505 |
,505 |
|
проживание |
11,551 |
11,551 |
11,551 |
11,551 |
11,551 |
|
образование(1) |
,204 |
,204 |
,204 |
,204 |
,204 |
|
образование(2) |
,287 |
,287 |
,287 |
,287 |
,287 |
|
образование(3) |
,209 |
,209 |
,209 |
,209 |
,209 |
|
образование(4) |
,234 |
,234 |
,234 |
,234 |
,234 |
|
стаж |
10,987 |
10,987 |
10,987 |
10,987 |
10,987 |
|
пенсстатус |
,953 |
,953 |
,953 |
,953 |
,953 |
|
пол |
,483 |
,483 |
,483 |
,483 |
,483 |
|
колвочл |
2,331 |
2,331 |
2,331 |
2,331 |
2,331 |
|
категория(1) |
,266 |
1,000 |
,000 |
,000 |
,000 |
|
категория(2) |
,217 |
,000 |
1,000 |
,000 |
,000 |
|
категория(3) |
,281 |
,000 |
,000 |
1,000 |
,000 |
В табл. 9 приводятся средние значения каждой переменной-предиктора и структура каждой ковариаты, заданная в поле «Plots» диалогового окна.
Четыре структуры ковариат соответствуют четырем категориям клиентов.
Эту таблицу удобно использовать при рассмотрении графиков выживаемости, которые строятся по средним значениям и структурам ковариат.
Заметим, однако, что «средних» клиентов на самом деле не существует, если мы посмотрим на средние значения переменных-индикаторов для категориальных предикторов. Даже, если у нас все предикторы будут количественными, маловероятно, что мы найдем клиента, для которого все значения ковариат будут близки к среднему значению.
Рисунок 7
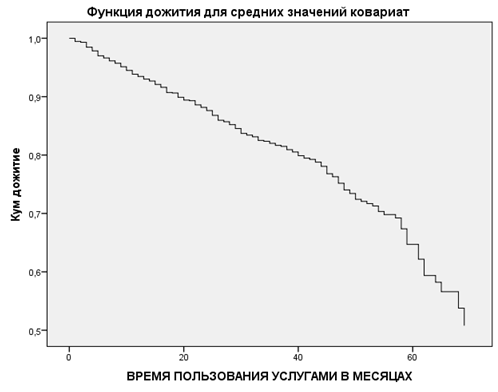
Кривая выживаемости на рис. 7 показывает время ухода, спрогнозированное моделью для «усредненного» клиента.
Горизонтальная ось — это время до наступления события.
Вертикальная ось — вероятность выживаемости.
Таким образом, каждая точка на кривой выживаемости показывает вероятность того, что «усредненный» клиент останется клиентом компании, «пережив» рассматриваемый отрезок времени.
По истечении 55 месяцев кривая выживаемости становится менее сглаженной. Речь идет о небольшом количестве клиентов, которые уже давно пользуются услугами компании. Доступной информации здесь мало и поэтому кривая становится разнородной по структуре.
Рисунок 8
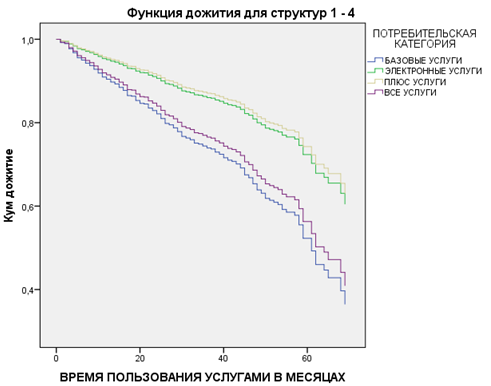
График кривых выживаемости, построенных для моделей ковариат (рис. 8), показывает результат включения в модель переменной [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ].
Для клиентов, выбравших пакеты «ВСЕ УСЛУГИ» и «БАЗОВЫЕ УСЛУГИ», кривые выживаемости расположены ниже, потому что, как мы уже знаем, исходя из коэффициентов регрессии, у них время ухода наступает раньше.
Рисунок 9
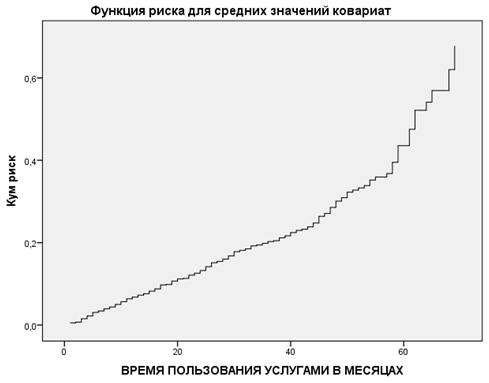
Кривая функции риска на рис. 9 показывает кумулятивную спрогнозированную возможность ухода для «среднего» клиента.
Горизонтальная ось — это время до наступления события.
Вертикальная ось — кумулятивный (накопленный) риск, который равен отрицательному логарифму вероятности выживаемости.
По истечении 55 месяцев кривая риска, как и кривая выживаемости, становится менее сглаженной по той же самой вышеуказанной причине.
Рисунок 10
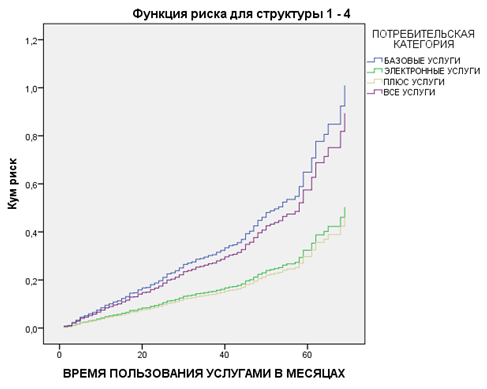
График кривых риска для каждой структуры ковариат (рис. 10) дает нам представление о влиянии переменной [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ] на модель.
У клиентов, пользующихся пакетами услуг «ВСЕ УСЛУГИ» и «БАЗОВЫЕ УСЛУГИ», — кривые риска расположены выше, потому что, как мы знаем из коэффициентов регрессии, у них время ухода наступает позже.
РЕЗЮМЕ
Используя регрессию Кокса, мы построили рабочую модель для прогнозирования оттока клиентов. Использование отдельных блоков для разработки модели позволило нам удостовериться в том, что переменная [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ] должна быть включена в итоговую модель. При этом мы воспользовались преимуществом пошаговых техник для включения других переменных в модель.
Чтобы построить модель, мы включили переменную [ПОТРЕБИТЕЛЬСКАЯ КАТЕГОРИЯ] во второй блок. Ее можно было включить и в первый блок, а пошаговые техники добавили бы другие переменные в модель во втором блоке. Модель в этом случае была бы той же самой, но так бывает далеко не всегда. Поэтому важно учитывать последовательность блоков и переменные в них. [an error occurred while processing this directive]
